Unicode Encoding Proposal for the Indus Script (Early Draft)
The Indus script is not deciphered yet. There is no consensus on what is and what is not a character. It is likely that many new characters will emerge in future excavations. Despite its aim of universality, the Unicode Standard considers writing systems for which insufficient information is available to enable reliable encoding of characters to be out of its scope. We are not at the stage where we can make a proposal for Unicode Encoding for the Indus script. We may not get there for decades to come. In the meantime, we still need some kind of a common encoding for people to record and share text. This section will outline a proposal for an encoding in the Private Use Area (PUA) of the Unicode Basic Multilingual Plane (BMP). The hope is that in the future this can be leveraged to an RFC to the community that defines what Unicode calls a “Private Agreement”. This will allow the community to agree upon a shared encoding and enable tools and technology like fonts and IMEs. This is an Early Draft of the proposal. Much of it will only make sense when one can read the words and texts of the Indus script. I will publish a decipherment separately. In the absence of a bilingual inscription, we have no authoritative source to determine the correctness of a decipherment. This paper describes a general method to do so based on the fit to data. The present decipherment fits a majority of the known inscriptions. The following proposal and discussion are based on this decipherment and may be somewhat cryptic to read until it is available. I humbly ask your patience in this regard.
Quick Summary
This proposal defines the range U+E8FF to U+F1AF in the Unicode BMP for the Indus script.
- A proposed Character Encoding Table
- Size of range: 2,225
- Number of Characters defined: 638
- Number of Characters reserved: 1587
This proposal attempts to conform to or enable the following Design Principles of Unicode:
- Characters, not glyphs: It specifies character encodings, not glyph forms.
- Stability: Once assigned, cannot be reassigned and key properties are immutable.
- Logical order: Articulating the default for memory representation.
- Specification of Bi-directional (Bidi) text handling
- Efficiency: Focusses on making Unicode text simple to parse and process.
- Plain text: It represents plain text not rich or structured text.
- Universal repertoire: The Unicode Standard provides a single, universal repertoire.
This proposal does not address or considers out of scope the following:
- Semantics: so that characters have well-defined properties.
- Unification: Unifying duplicate characters within scripts across languages (e.g. Egyptian Hieroglyphs)
- Dynamic composition: Accented forms can be dynamically composed.
- Convertibility: Guaranteeing convertibility with other standards.
- Unicode Character Database and formal semantics
- Tailorings for Unicode Common Locale Data Respository (CLDR)
- Specification of Collation methods or weights.
- Emoji
Background
The Indus Script has survived in the form of seals with relatively short inscriptions of 4-5 characters. The earliest seals discovered so far come from about 3,500BC but the majority are from the Mature Harappan Period of 2,600-1,900BC. Only a few thousand seals have been found, out of which 40% of the seals have an illustration apart from text, of those more than half are that of a Unicorn bull. There is no long-form script available to us.
This relative scarcity of information has made it difficult to decipher the script. Also, unlike Egyptian Hieroglyphs which had the Rosetta stone and Cuneiform which had the Behistun inscription, there has been no bilingual inscription discovered so far. In its absence, we have no way to learn from someone who knew. Any attempt to decipher the script, including the current one, is a guess that may or may not be correct. There is no logical way to eliminate possibilities down to a single one.
There has been speculation that the Indus script was not a script at all. The inscriptions are too small compared to other known scripts and could not represent something as complex as language. That there were too many “singleton” characters (characters that occur just once in the whole corpus). This, however, is not necessarily true. In many ways, the Indus seals are quite similar to Japanese hankos or personal seals. Hankos are used to sign contracts or authorize bank transactions. Most hankos range between 2-4 characters and are enough to serve an economy of the scale of Japan.
As an example, if we were to take the train station names across Japan and make “seals” of them, we would get about 8,850 names as in Figure 1(a). This is somewhat comparable to the 4,615 Indus seal inscriptions in the Indus corpus. We find that each seal in Japan would, on the average, have about 3 characters, whereas the corresponding number is about 4 in the Indus case. The modern script is actually more terse. This is not surprising because it has a greater number of unique characters. Both have a large number of singletons, although the Indus script has a slightly higher number at 33.85% vs. 25.95%. It is important to note that even in the Japanese case, for random samples of 4,615 names we get an average of 31.65% singletons. As we see in Figure 1(b) and 1(c), their relative character distributions also have similar long tails.
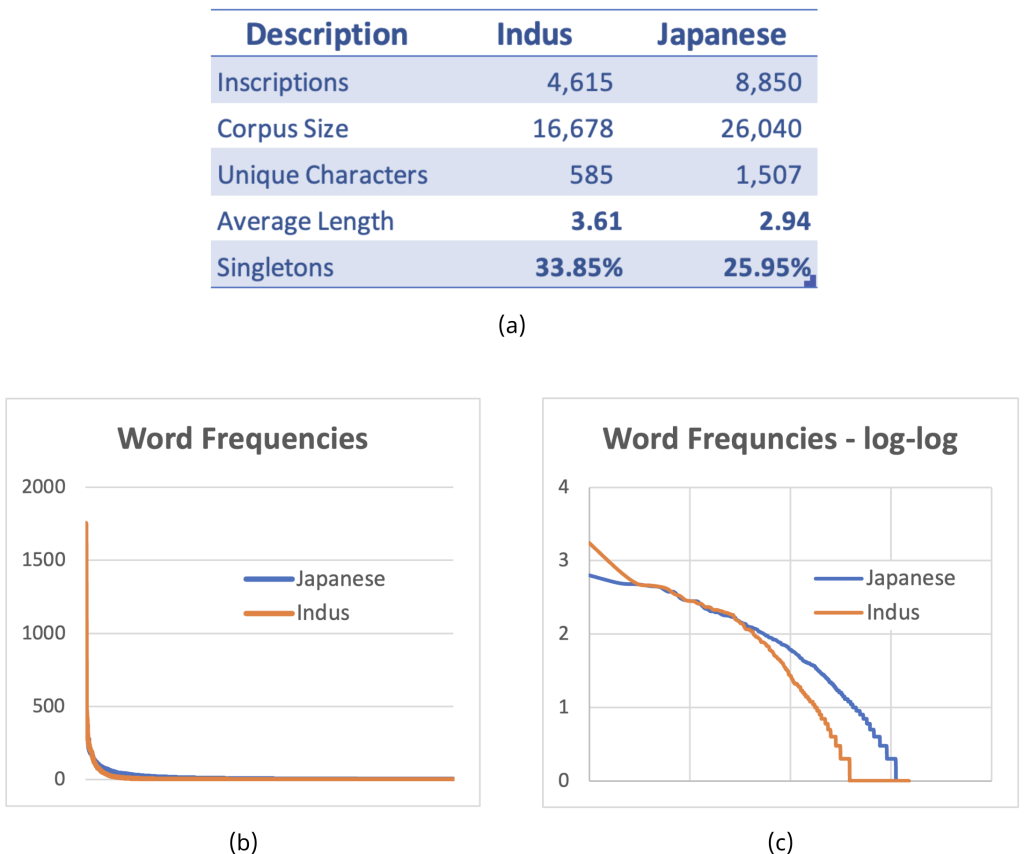
The Japanese corpus includes 1,507 unique Kanjis versus the 586 unique characters in the Indus. While the Japanese number is larger, it does represent the full range place names of one of the largest of modern economies, more than an order of magnitude greater in population compared to the Indus and a much later stage in the evolution of the script – i.e. the literature available in Japanese today and the complexity of what it represents is considerably greater than the Indus script would have had in its time. Even though such metrics cannot represent the complexity of either script, but all things considered, they are surprisingly comparable.
Characters, not glyphs
Unicode considers characters to be the smallest component of a written language that has semantic value. As an example, a given character or piece of text may be written in multiple fonts, each of which can have very different appearances, but they all represent the same text, the same characters. So when you search for a word, you don’t need to remember or specify what font you wrote it with, just the word because the text is represented in characters, not glyphs. The glyphs that one font uses to represent a character can be wildly different from another but they represent the same character. It is the character that receives a Unicode code.
There are two major kinds of scripts in broad use – phonetic scripts and ideographic scripts. Phonetic scripts, like the alphabet, represent sounds and we write a word by how we hear it. In a logographic or Ideographic script, like the Han characters of CJKV (Chinese-Japanese-Korean-Vietnamese) scripts, a character represents a meaning. They generally have one root meaning and retain their semantic content across linguistic boundaries. Instead of understanding what text means by hearing it, we can recognize it by seeing it. It gives communication a visual metaphor.
The Indus script is Ideographic. The characters encode meaning. It is peculiar that even as far as today we do not have a name for these characters. I will call them Akhyats. “Akhyat” in Sanskrit means “that which brings to cognition” or “announced, named”. The more familiar “Vikhyat” means “famous or easily recognized” and comes from the same root.
Akhyats are in many ways like CJKV ideographs, and like them, they were most likely used to encode multiple languages. In fact, this is also why Indus inscriptions are terse. They need fewer characters. Unlike a phonetic script like the alphabet where two characters can at most represent 26×26 (676) combinations, in an ideographic script like the Indus, two characters could potentially represent (638×638) more than 400,000. In a CJKV script this number is many orders of magnitude larger. Like any script, not all combinations are valid, but there is no doubt that one needs fewer ideographs to specify the same word compared to phonetic characters.
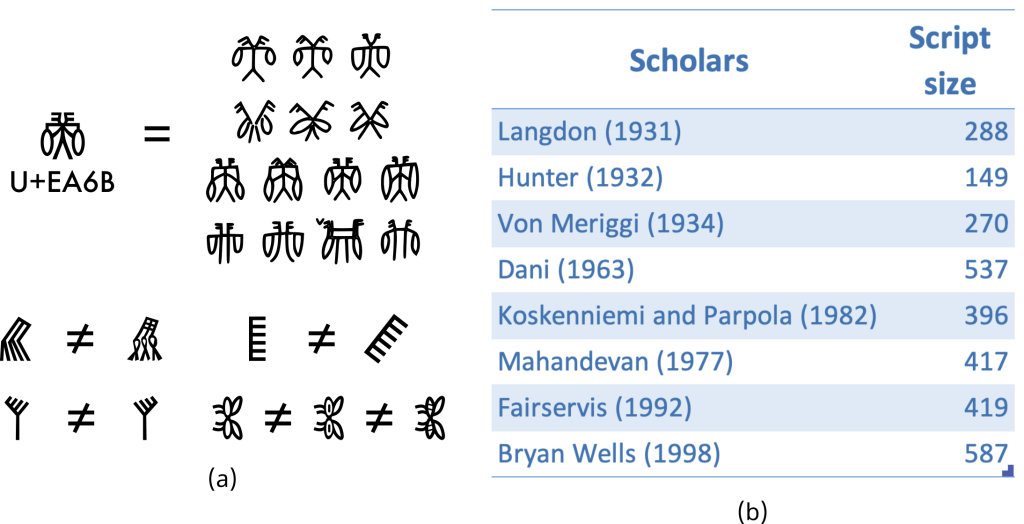
One of the primary tasks to create a Uncode encoding of Akhyats is to define what an Akhyat is. When do two glyphs mean the same thing and when do they not. In Figure 2 (a), the top shows the same Akhyat in different glyphs or styles found across the corpus. In the bottom we see different Akhyats that look similar but are different. Akhyats can look quite different without any change in its semantic content and yet can look very similar and mean something different. This can sometimes be reasonably obvious to see, but many times it is not. In Figure 2(b) we see the many widely varying Akhyat counts from different studies because of this.
The only way to reliably define the set of Akhyats in the Indus script is by reading them. One needs a decipherment. In the absence of a bilingual inscription, in the absence of an authoritative source telling us what the Akhyats meant, any attempt at listing them is an interpretation. It is a guess, and guesses can be wrong. We need some way to validate whether one is right.
There is a way to do this. We create a dictionary definition for all Akhyats at once. We then see if we can meaningfully read all the seals and inscriptions given this definition. If the Akhyat’s glyph drawing also happens to convey the same meaning, it is further confirmation, but oftentimes the match is not specific. Han characters evolved into abstract strokes that are unambiguous rather than remain pictograms with many potential interpretations.
Although such a dictionary definition is not guaranteed to be unique or correct, in practice it is incredibly difficult to do. It is not easy to “fit” a set of meanings so that one can read all the text. When it occurs, even in part, such an assignment is quite robust and changes very slowly. If the set of seals that one can read crosses 50% of the corpus, this stability is not likely to be a coincidence. If it further provides reasonable explanations for known facts and gives verifiable and/or verified predictions of things not known, it becomes a generic methodology to validate a decipherment even when there is no authoritative source.
In its essence, this method is inspired by the way a machine learns in AI. We are, in effect, trying to fit a model to the data. It is more like a scientific theory than a “logical” argument. And unlike many arguments that selectively focus on some elements while ignoring the rest, this addresses all of them, all the time. It can give surprisingly good results when it finds a good fit. But it can only speak to validity, not truth.
Using this, if two glyphs occur in roughly the same contexts and mean roughly the same, they maybe the same Akhyat if they are written in similar but different glyphs. Similarly, if the same Akhyat reads differently across many contexts, it is possible that it corresponds to more than one Akhyat and we might be missing something subtle.
The above method does not prescribe how one finds a reasonable mapping in the first place, only the means to evaluate it. I have spent over 10 years attempting to decipher the script and for the past 4 years I have been able to read more than 80% of the Indus characters and published seals. This interpretation represents a large-scale attempt to do the above.
The definition of Akhyats in this proposal is based on this “decipherment”. But it is by no means normative. Although the bulk has not changed for years, every time I go through the corpus, I discover things I missed or got wrong. And there is always to chance of a breakthrough realization needing large scale changes. One of the Design Principles of Unicode is Stability, that once a character is assigned it cannot be reassigned, its definition must be immutable. This is a high bar. We are not there yet, and we are not going to get there any time soon. This proposal is a Private Agreement and can afford to change. The hope is that over time we will get a definition stable enough to consider a formal Unicode proposal.
We are choosing to use the PUA of the Unicode Basic Multilingual Plane for this. We have a choice of three possible PUAs, one in the BMP and two larger areas in Plane 15 and 16 respectively. We are going with BMP because we do not need the larger space and BMP is more likely to have support in older e-readers and devices/software. We are reserving a range of 2,225 codepoints and is about the same order as Joyo Kanji (2,136) which is a normative list from the Japanese Ministry of Education to define the minimum requirement to get into college. We have assigned 638 so far, but this has been done with enough headroom to accommodate future Akhyats that we discover as well as establish areas for legacy characters to provide compatibility with or deprecate. While one would like to create a safe playpen to “Fail fast, fail often, learn and try again“, the truth is that any change may be disruptive to texts that have already been written in a previous version. This needs to be managed in terms of Versioning and Deprecation and Backward Compatibility where possible. Ideally, one wants a slow-moving target.
Direction of Writing and Unicode BiDi
One of the aspects of the Indus script where there is relative consensus among scholars is the direction of writing. It is Right-to-Left for the most part. This is apparent in some seals where the sculptor ran out of space as they went to the left as we can see in the seal of Figure 3(b). It is even more evident in Figure 3(c) where the text wraps Right-to-Left, Top-to-Bottom, and then Left-to-Right; where the bottom line is written upside down and is the only place in all the corpus where these Akhyats are upside down. The table shows some of the most frequent words in the script and there is an overwhelming preference for one direction. The last line in the table shows the first two Akhyats of the seal of Figure 3(c). Thus means these characters were read Right-to-Left. The third line, also in the seal, is also in the same Right-to-left direction. The Right-to-Left direction quickly extrapolates across the entire corpus from the strong direction preference and the reading direction in this seal.
| Word | Freq | Reverse | Freq |
|---|---|---|---|
| | 174 | | 5 |
| | 90 | | 4 |
| | 145 | | 3 |
| | 40 | | 1 |
| | 45 | | 3 |
| | 14 | | 0 |

- Right-to-Left: e.g.
- Left-to-Right (Mirrored): e.g.
- Left-to-Right (Symmetric): e.g.
- Left-to-Right (Shuffled): e.g.
Right-to-Left is the most common pattern but we find Left-to-Right as well as mirror or not mirrored forms.
- Right-to-Left: 94.2%
-
Left-to-Right: 5.8%
- Mirrored: 2.7%
- Symmetric: 2.7%
- Shuffle: 0.4%
Unicode standardizes the Logical order of Characters in the text. This is the sequence of the characters in memory. Essentially this is how we store our text in a file, how algorithms like search work with text and many other things. The specification says that we should store the characters similar to how we would enter them on a keyboard. In the case of the Indus script this would Left-to-Right. We would type as ① ② ③ . This is the sequence that would be stored on file as well as made available to all programs. The text rendering directionality would be implemented by Unicode’s standard BiDi algorithms.
In our case, since we are assigning the Akhyats to code points in the PUA, we cannot leverage the standard Unicode BiDi algorithm. We cannot specify directionality within each Character’s properties as we cannot define them. But, we can use standard css styles and Unicode directional formatting characters. Please note that these directional characters may have varying levels of support in real software. Many ereaders and others may strip them out. They can also be an attack vector for malware and social engineering plays in some cases. As an example, although not a representative one, a file called “name-txt.exe” can look like “name-exe.txt” if one places a right-to-left override where the hyphen is. It may get somebody to execute it by thinking it was a document. Varying softwares may intentionally highlight Bidi characters as a control character by displaying a box prominently around. This may make it awkward to read the text. The Unicode Bidirectional Algorithm formatting characters can be equivalently represented by stylesheets or markup. Conflicts can arise if markup and explicit formatting characters are used together. Where available, markup should be used instead of the explicit formatting characters. As an example:
- Right-to-Left: <span style=’direction: rtl; unicode-bidi:isolate-override;’></span> gives .
- Left-to-Right: <span style=’direction: ltr; unicode-bidi:isolate-override;’></span> gives .
Since the PUA cannot leverage standard Unicode mechanims for handling mirror forms, the ida font comes in two varieties – Ida-Regular and Ida-Left-To-Right. The same character can be reflected simply by changing the font.
There are many limitations in the proposed scheme because it is using the PUA with no formal support from Unicode. But it is a starting point. One thing to bear in mind is that it is important that all text we encode must be in the standard Logical order (left-to-right) so as to give a standard scheme for tools like search and others. It will be impossible to change this along the way. We must follow Unicode standard right from the start regardless of the teething difficulties we may have with limited Unicode support for the PUA encoding.
Canonical Decomposition and Canonical Order
An Akhyat corresponds closest to what Unicode would call a base character in the Ideograph sense but there are punctuation characters, digits and digit-like characters, and perhaps most importantly compounds, sometimes similar to the CJKV sense and sometimes not.
First of all, there are rare instances where the Indus script is used phonetically where each Akhyat represents a single phonetic character. Perhaps the most famous of these is the Dholavira signboard: which is an example of phonetic usage. Both vowels and consonants are represented. Unlike abjads like the original Phoenician script, here both vowels and consonants are represented as well as long and short vowels are distinguished. The semantic characteristic of the Akhyat is not completely lost in such usage. The Akhyats chosen are “poetically related” in meaning with relation to the word but they primarily represent sound. The same name in Akhyats would be written with two Akhyats. In this inscription, it is interesting to observe that the Akhyats are in their proper Right-to-left direction even though the text itself is written from Left-to-Right. It is tempting to think the Akhyats face you as you read them and in 99% of the inscriptions they do, but they don’t in this one.
There are some other examples like , and others. But less than 1% of the inscriptions discovered so far are used in this phonetic way. For the rest of this proposal we will ignore them and focus on outlining Akhyats that are ideographs.
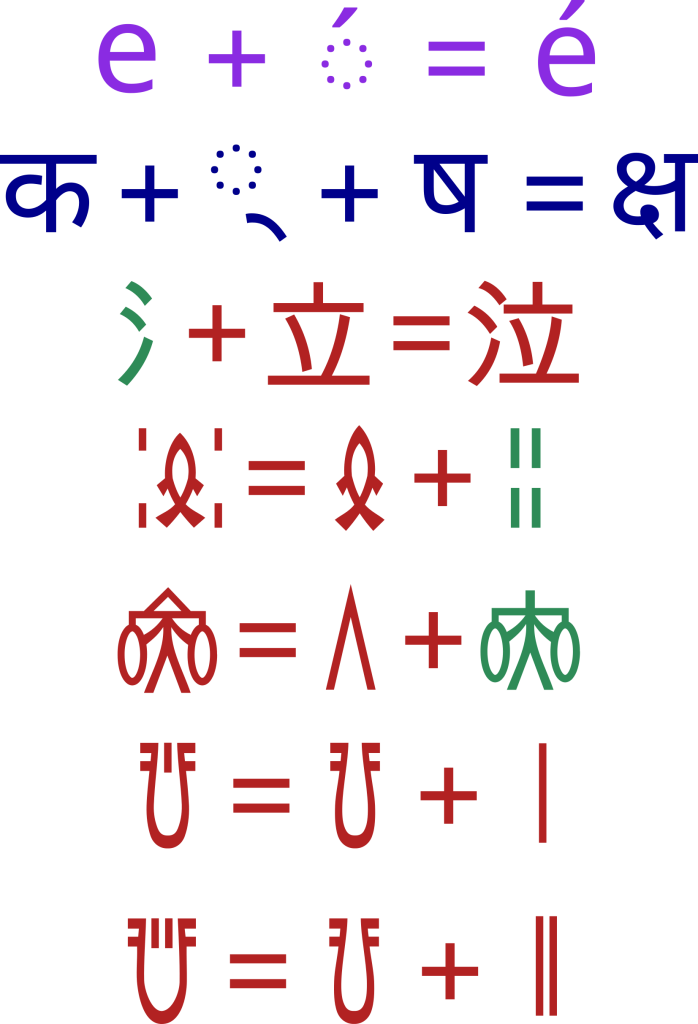

Unicode distinguishes between base characters and those that are derived from the combination of other characters. As an example, in Figure 4, we find an accented e which has a different Unicode code than e or its accent but is essentially a “precomposed” character. Unicode defines a canonical decomposition into its constituents such that two strings may be compared reliably. These normalized decompositions are defined for all such precomputed characters. There is another kind that is found in Indic and complex scripts where two characters combine to form a new glyph but this precomposed form is not assigned a Unicode codepoint. Instead it is handled by the font and rendered on the fly. There are well-defined rules for such composition that typically come from the language itself and encoding them with codepoints would unnecessarily use up many thousands of slots.
In CJKV scripts base forms combine to form a new character that is assigned a separate Unicode codepoint. In the third line of Figure 4 we have the Han character for “tear”, like a tear drop, which is composed from the characters of “water” and “to stand”. While the composition is poetically formed from the other two characters there is no doubt it is a separate meaning. One character contributes the core meaning from which the final character is derived and the other specifies the sound. This is called a Phono-Semantic Compound. The character in green, water, specifies the meaning water and is called the radical of the phono-semantic compound and serves as the key to looking up the word in a dictionary. In fact, more than 90% of the Chinese characters come from this same generative process. Each such compound is assigned a separate Unicode codepoint because it has a different meaning.
Indus Compounds and Decomposition
Indus script also has phono-semantic compounds although more often than not the compounds are not phono-semantic. In the 4th and 5th lines of Figure 4, we can decompose the Akhyat according to phonetic and radical components in exactly the same fashion as a Han compound. The resulting ideograph can and should be assigned a Unicode codepoint separate from the constituent Akhyats because it is not an obvious composition of the two, and has a meaning different from both. But the majority of the compounds in the Indus script are not phono-semantic. They are often closer to compound nouns like “computer science” where both characters participate in the specification of meaning. Examples of this are in lines 6 and 7. A basic breakdown of the types of Indus compounds is as follows:
- Base Akhyats – 265
- Compound Akhyats – 315
- Phono Semantic Akhyats – 55
- Punctuation: 3 Akhyats –
So how does one handle these compounds? Can they be precomposed forms like the accented “e” or can they be rendered as a font artifact like the ligatures of a complex script. In order to answer this we need to note a fundamental different between all ideographic scripts and phonetic ones, one deals with sounds and the other with meanings. In the case of sound we can compose adjacent characters in a sequence because sound itself composes locally, that is, there is no long range correlation between a sound and one that occurred some time ago. The same is not true with ideographs as the composition of two adjacent characters is dependent on context that could be defined much earlier in the sequence.
Let us take the bottom two lines in Fig. 4. +=, can we canonically break down this compound into those two Akhyats, i.e. whenever we encounter them are they canonically equal to the compound Akhyat? This is generally not the case. Interestingly for this Akhyat it may well be true. There are only 2 inscriptions where we encounter the two constituent Akhyats separately. 206 times they are precomposed into the compound, so effectively, the Indus scribes had already precomposed them.
The same is not true of the second example += . The compound occurs only 41 times in the corpus whereas the consitituents occur separately 68 times like in . In actual fact, it is not possible to combine the two Akhyats into the compound in this case because they would mean something different. A rough analogy of this can be seen in English. “computer science” is different from “science computer” so the sequence order matters; which is fine because unicode maintains this sequence in its definition of Logical order. But, is “(computer science) department” the same as “computer (science department)” – most probably not. This combination is not merely dependent on sequence adjacency but has a longer range correlations to a broader context. As an “algebra” it is neither “commutative” nor “associative”.
Indus compounds cannot be canonically decomposed, in the Unicode sense, to its constituent base Akhyats. They must be assigned separate codepoints. I suspect this is generally true for all Ideographic scripts.
This is not to say that having a representative decomposition is not useful. As an example, a search engine may want to enrich indus text to match components, like a search for should match both and . But when we encounter compounds in the Indus script, like the phono-semantic case, they have a meaning that is different from the mere composition of its base Akhyats, and therefore need a separate Unicode codepoint to represent them. “computer science” means something specific and is not just an intersection of “computer” and “science”. From this perspective they are similar to Han characters and we can treat them exactly in the same way. In fact, it almost feels like the phono-semantic nature of Han characters is a natural and later stage of evolution from what we see in the Indus.
A Road to a Canonical Order
How do you sort Indus text? This is a matter of great significance. Without the “alphabetical order” in would be hard for us to search for books in a library or even look up a word in a book index. One could argue that the “Qwerty” system is more efficient in someways but having a generally accepted scheme has a value independent of the value of the scheme itself. Indeed, there can be multiple competing orders but it is important to have one widely adopted, universal order. It is inevitable that the ordering of the Akhyats in the Unicode encoring will likely be the defining one.
Unlike the ordering in a script with a few dozen characters where any order can do, a script with several hundred or thousands needs to be well-thought through. In the Indus case this has immediate relevance because in the absence of IMEs that can covert phonetic input to the corresponding character, we have no option but scrolling through a list of all of them every single time we want to input one.
In the 2nd century AD, Xu Shen organized the first etymological dictionary he called Shuowen Jiezi by selecting 540 radicals, the semantic component of a phono-semantic compound. This served as the basis for partitioning the dictionary. As an example, the character for “tear” in the Figure 4 would be listed only under the “water” radical.
Mei Yingzuo’s 1615 dictionary Zihui made two further innovations. He reduced the list of radicals to 214, and arranged characters under each radical in increasing order of the number of additional strokes – the “radical-and-stroke-count” method still used in the vast majority of present-day dictionaries.
While the number of Akhyats discovered so far is far less, in the hundreds rather than tens of thousands for Han characters, it is still enough to make search non-trivial and memorizing a linear order impractical. One cannot really use the “radical” method as the use of phono-semantic compounds was not as wide spread. Also, there is much more visual information in the Indus glyph that was abstracted away in later Han characters as that script grew more complex. But the idea of classes or grouping based on related meaning can find a similar expression in the Indus case.
Etymology Classes and Systematic Polysemy
This proposal partitions the space of Indus Akhyats into 108 Etymology Classes. The classes are derived from commonality based on meaning. There are a few large blocks further grouping classes themselves. The U block is essentially the “tomb of the unknown character”. In any inscription, where the character is missing or damaged or we simply cannot read it, we use this character to specify that the character is not known. The N block is organized based on numbers although the Indus used numbers for various purposes in the script. The P Block corresponds to Akhyats related to peoples in the Indus civilization. The G Block organizes Akhyats related to places or geographies. The PxG Block is a set of place names that are associated to a people as France is to the French. The O Block contains various other groupings. Each of these classes have considerable headroom to incorporate new Akhyats while maintaining the same overall order.
The Indus Encoding leverages the following structure to layout a canonical order for the Indus script.
- Etymology Classes – 108
- Chiral Forms – 59 pairs
- Bent Forms – 73 pairs
- Black and White Forms – 17 pairs
It is hard to describe Etymology classes without explaining what each means. A full explanation of this section will need to wait for the decipherment book to be published. But the logic being used may be visible just from the glyph forms to a limited extent. As an example, the four Akhyats in block P-7 are obviously related. All the classes in the N-Block (N1 to N18) have a similar relationship based on the numbers they represent. In general, various compounds are grouped according their corresponding base form like in G-22. Phono-semantic compounds like
are grouped according to the semantic component rather than the sound component . This has the added benefit of distributing them over a number of blocks instead of clustering them in one. It is important to realize that unlike the Han dictionaries phono-semantic compounds do not have the same level of systematic and standardized use in the Indus script. Block P-6 clusters phono-semantic compounds based on their sound rather than radical and I suspect this is indeed how the Indus viewed them because the most important Akhyat in their glyphs is the sound component. In the case of compounds, like , we organize it by the narrower component, in this case by instead of . This is like cataloging “Brooklyn Bridge” under “Brooklyn” instead of “Bridge” because it would easier to find in things related to Brooklyn rather than all things “bridges”. It is important to note that the narrower category is defined semantically rather than by frequency of usage. is found in 447 inscriptions rather than which is found only in 147.
I realize that this is a cryptic and incomplete description. I will come back to this once my decipherment book is published and explain each element in detail. But this is to give a flavor of the kind of considerations went into the design of the Etymology classes. There is no one right answer. Most of it comes from clustering what was useful given the need to find Akhyats in normal usage.
There is another form of natural organization that is present in the Indus. This is Systematic Polysemy. Systematic Polysemy occurs in various forms in many languages. In English the word “rabbit” can mean both the animal as well as its meat. This is used systematically to generate similar related meanings across a number of words related to animals like chicken, fish, rabit, lamb, etc. Similarly, the Indus script uses various glyph transforms to generate a form of systematic polysemy. This does not really have a counterpart in the more abstract Han characters. These are of the following types – Chiral Forms, Bent Forms and Black-and-White Forms.
Let us take versus . The central Akhyat of each is a reflected image of the other. These are called Chiral forms. They are different Akhyats but very closely related to one another. They really differ in just one aspect. In a sort, we would ideally like to have these two right next to one another. We achieve this by not only placing them in the same Etymology Class but right next to one another. This allows for the standard unicode encoding itself to keep them together in the sort. So everywhere we encounter Chiral forms we place them together. Everywhere there is a reasonable possibility that a chiral form may emerge in the future, we leave a gap in the encoding to accommodate it. The same is true of Bent Forms like and of Black-and-White forms like .
Naturally, the proposed encoding will allow one to sort Indus text in a Universal Canonical order based on these Etymology classes and this order will be available to all software by default. In effect, it is the same as the alphabetical order in English. But it is important to remember that this is just one order. Just to end out the section on a Canonical Order, the following is taken from the Unicode standard for collation and applies just as well to the Indus case.
- Collation is one of the most performance-critical features in a system.
- Collation is not code point (binary) order.
- Collation is not aligned with character sets or repertoires of characters.
- Collation is not a property of strings.
- Stability is a property of a sort algorithm, not of a collation sequence.
- Collation order is not preserved under concatenation or substring operations, in general.
Versioning, Deprecation and Backward Compatibility
As our understanding of the Indus script evolves this encoding will need to evolve as well. This is an Early Stage Draft and will likely change in the coming weeks and months. Also, while this proposal is my best effort to create a reasonable encoding, it can be wrong. As I engage with the community and they have had chance to reflect their needs into this, newer and better methods of organization may emerge. We need a method to incorporate change until the requirements for change begin to subside. To put some method in the madness, I propose the follow versioning scheme.
Currently everything is pre-release meaning it does not have a version. It is given “as-is, where is” and everything can and will change. I am dogfooding this over my various projects so as to get to a reasonable initial state. Even after release of my decipherment and for a time that the community feels necessary this will continue in this pre-release state until people have had a chance to study it and engage with it.
Once released, versioning will start from 1.0.0 and go monotonically upwards. All versions will be retained in a central site. Each version should ideally release a corresponding font (where necessary) so that the community can see the change. Versioning is divided into major.minor.point releases.
A major release is one where we have breaking changes, which means that an existing character is changed – moved, deleted, etc. Every such character will be moved to a well-defined code in the Deprecation Block O-6 and people can “search-replace” such characters in existing texts so that they continue to be readable. People may also be able continue using a previous version by embedding the corresponding font.
A minor release is one where new characters are added without affecting any existing character. This means that all existing texts can continue without change and any software may upgrade to the new characters, if necessary.
A point release means that there is no change in the character assignments but something else has changed and should not affect any existing documents or applications.
Since the versioning explicitly allows for breaking changes, backward compatibility can only be offered to a limited extent through the Deprecation block. Tools and even texts can note what version they require. People should consider embedding an equivalent font so that a text written will continue to be readable where appropriate.
This proposal is merely a suggestion to provide a starting point for discussion. Please feel free to get in touch and suggest improvements or changes.